【置顶】Lite2D的渲染线程尝试
项目地址 https://github.com/dreamyouxi/Lite2D
注意:
1.GL只能和一个线程相关,所以纹理产生,初始化等都要放到渲染线程。
2.双缓冲默认是垂直同步的 可用 glfwSwapInterval; 来设置
GL API 参考自 http://www.glfw.org/docs/latest/group__context.html
暂且用以下方案:
1.渲染线程拷贝一个主线程产生的 纹理(暂定)
2.遍历Node的时候吧渲染参数 包装为命令(RenderCmd) 放到渲染队列里面(RenderCmdQueue)
3.因为线程安全问题,GL相关操作都用回调 在渲染线程来处理
逻辑线程执行的时候 会强制同步到渲染线程

逻辑帧数60,渲染帧数11999,逻辑延时0.000467 MS,测试平台 i7 4790K GTX 950
帧数限制:
通过最大帧数的时间来控制渲染次数,当渲染次数和逻辑次数不匹配会自动丢帧,保证当前渲染的始终是最新帧
static void ThreadFunc(RenderCmdQueue * reder)
{
Director::getInstance()->getGLView()->init(); // init gl in render thread
LARGE_INTEGER nLast;
LARGE_INTEGER nNow;
QueryPerformanceFrequency(&nFreq);
perFrame.QuadPart = (LONGLONG)(1.0 / DEFAULT_FPS* nFreq.QuadPart);
QueryPerformanceCounter(&nLast);
float delta = 0.0f;
while (true)
{
QueryPerformanceCounter(&nNow);
if (nNow.QuadPart - nLast.QuadPart > perFrame.QuadPart)//default fps is 120
{
delta = (float)(nNow.QuadPart - nLast.QuadPart) / (float)nFreq.QuadPart;
reder->render();
reder->setRenderFPS(1.0f / delta + 1);
nLast.QuadPart = nNow.QuadPart;
}
else
{
//std::this_thread::sleep_for(std::chrono::microseconds(0));
}
}
}
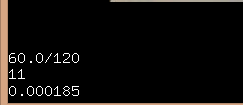
demo项目表现良好

渲染命令
//.h
class RenderCmd :public Ref
{
public:
virtual void exec(Texture2D*) = 0;
float *_coord2f = 0;
Vec2 _vertex[4];
float _opacity = 0.0f;
Texture2D*tex=nullptr;
};
class RenderCmd_Quad :public RenderCmd
{
public:
virtual void exec(Texture2D*)override;
};
//.cpp
void RenderCmd_Quad::exec(Texture2D *tex)
{
GLuint id = tex->getTextureID();
tex->getFileName().c_str();
glLoadIdentity();// vetex can work once
glBindTexture(GL_TEXTURE_2D, id);
// able alpha blend for the texture who has alpha
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
//able opacity
glEnable(GL_ALPHA_TEST);
glAlphaFunc(GL_GREATER, 0.0f);
glTexEnvf(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_MODULATE);
glColor4f(1.0f, 1.0f, 1.0f, _opacity);
//start to render
glBegin(GL_QUADS);
glTexCoord2f(_coord2f[0], _coord2f[1]); glVertex2f(_vertex[0].x, _vertex[0].y);
glTexCoord2f(_coord2f[2], _coord2f[3]); glVertex2f(_vertex[1].x, _vertex[1].y);
glTexCoord2f(_coord2f[4], _coord2f[5]); glVertex2f(_vertex[2].x, _vertex[2].y);
glTexCoord2f(_coord2f[6], _coord2f[7]); glVertex2f(_vertex[3].x, _vertex[3].y);
glDisable(GL_BLEND);
glDisable(GL_ALPHA_TEST);
glEnd();
}
渲染队列(渲染线程)
class RenderCmdQueue
{
public:
void addFuncToRenderThread(const std::function<Texture2D*(void)> &func);
void addCustomFuncToRenderThread(const std::function<void(void)> &func);
private:
std::unordered_map<std::string , Texture2D*> tex_pool;
std::vector<std::function<Texture2D*(void)>> _func;
std::vector <std::function<void(void)>> _func1;
void processOtherThreadFunc();
std::mutex _mutex;
public:
static RenderCmdQueue*create();
void addRenderCmd(RenderCmd*cmd);
void clear();
void NextTick();//thread safe
void draw();
void setVerticalSynchronization(bool enable);
private:
std::atomic<bool> isNextTick = false;
std::vector<RenderCmd*> _queue;
void clearAllRenderCmd();
RenderCmdQueue()
{
_queue.reserve(200);
}
};
//cpp
static void ThreadFunc(RenderCmdQueue * reder)
{
Director::getInstance()->getGLView()->init(); // init gl in render thread
LARGE_INTEGER nLast;
LARGE_INTEGER nNow;
QueryPerformanceFrequency(&nFreq);
perFrame.QuadPart = (LONGLONG)(1.0 / 120 * nFreq.QuadPart);
QueryPerformanceCounter(&nLast);
float delta = 0.0f;
while (true)
{
QueryPerformanceCounter(&nNow);
if (nNow.QuadPart - nLast.QuadPart > perFrame.QuadPart)
{
delta = (float)(nNow.QuadPart - nLast.QuadPart) / (float)nFreq.QuadPart;
reder->render();
reder->setRenderFPS(1.0f / delta + 1);
nLast.QuadPart = nNow.QuadPart;
}
else
{
//std::this_thread::sleep_for(std::chrono::microseconds(0));
}
}
}
RenderCmdQueue* RenderCmdQueue::create()
{
RenderCmdQueue*ret = new RenderCmdQueue;
//Director::getInstance()->getGLView()->init();
/*std::thread t([ret]()
{
Director::getInstance()->getGLView()->init();
while (true)
{
ret->draw();
// Sleep(100);
}
}); t.detach();*/
static std::thread t(&ThreadFunc, ret); t.detach();
return ret;
}
void RenderCmdQueue::addRenderCmd(RenderCmd*cmd)
{
_mutex.lock();
_queue.push_back(cmd);
_mutex.unlock();
}
void RenderCmdQueue::clear()
{
isNextTick = false;
_mutex.lock();
++_tick_status;
if (_tick_status > 5)
{
_tick_status = 0;
auto dir = Director::getInstance();
_cache_fps = dir->getFPS();
_cache_last_fps = this->getRenderFPS();
_cache_redertime = dir->getRenderTime();
}
this->clearAllRenderCmd();
_mutex.unlock();
}
void RenderCmdQueue::setVerticalSynchronization(bool enable)
{
if (enable)
{
glfwSwapInterval(0xff);
}
else
{
glfwSwapInterval(0x0);
}
}
void RenderCmdQueue::NextTick()//thread safe
{
this->isNextTick = true;
}
void RenderCmdQueue::clearAllRenderCmd()
{
for (int i = 0; i < _queue.size(); i++)
{
_queue[i]->release();
}
_queue.clear();
}
void RenderCmdQueue::render()
{
do
{
if (isNextTick == false)break;
std::lock_guard<std::mutex> lock(_mutex);
// if (_queue.empty())break;
glClear(GL_COLOR_BUFFER_BIT);
// glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glEnable(GL_TEXTURE_2D);
for (int i = 0; i < _queue.size(); i++)
{
RenderCmd *cmd = _queue[i];
auto it = tex_pool.find(cmd->tex->getFileName());
if (it == tex_pool.end())
{
Texture2D* tex = new Texture2D;
auto image = new Image;
image->initWithFile(cmd->tex->getFileName());
tex->initWithImage(image);
cmd->exec(tex);
tex_pool[cmd->tex->getFileName()] = tex;
}
else
{
cmd->exec((*it).second);
}
}
glDisable(GL_TEXTURE_2D);
Director::getInstance()->getGLView()->swapBuffers();
} while (false);
this->processOtherThreadFunc();
}
void RenderCmdQueue::processOtherThreadFunc()
{
_mutex.lock();
for (auto &func : _func)
{
Texture2D* tex = func();
tex_pool[tex->getFileName()] = tex;
}
_func.clear();
for (auto &func : _func1)
{
func();
}
_func1.clear();
_mutex.unlock();
}
void RenderCmdQueue::addFuncToRenderThread(const std::function<Texture2D*(void)> &func)
{
this->_mutex.lock();
_func.push_back(func);
this->_mutex.unlock();
}
void RenderCmdQueue::addCustomFuncToRenderThread(const std::function<void(void)> &func)
{
_mutex.lock();
_func1.push_back(func);
_mutex.unlock();
}
实测,当object很多时候 渲染效率反而底下,比如1万个同纹理的 单线程依然50+FPS 多线程版本就只有20+FPS,